

Google Webmaster Conference Product Summit Recap

Last week, Google held its first Google Webmaster Conference Summit at the GooglePlex in Mountain View, California to help webmasters optimize their sites for Search. Google has hosted Webmaster Conferences throughout the world, but this is the first time they’ve held it at the GooglePlex. And unlike other Google conferences, this was a full-day event.
For an in-depth overview of the Google Webmaster Conference Summit, check out Jackie Chu’s blog. If you need an introduction to Search and the Web, we recommend watching Google’s “Search for Beginners” web series.
There was a lot of useful information provided by industry experts and the Google Search Team at the first Webmaster Conference Summit in Mountain View, CA. Here’s a recap.
Keep in mind that many of the Search techniques described below are best handled by a professional SEO and digital marketing agency. If you have any questions, don’t hesitate to contact us.
Google Webmaster Conference Product Summit Recap
Web Deduplication
Duplicate content is when you have multiple pages on your website with identical or largely identical content. Some examples of duplicate content include printer-only versions of web pages, mobile and desktop versions, and duplicate content on city pages.
If you do have pages with duplicate content, it’s important to tell Google which page is your preferred URL by using “canonicalization.” If you don’t tell Google which URL to prioritize, they will decide for you.
You can find out which pages Google considers canonical by using their URL Inspection Tool. Follow these best practices when using a rel=canonical link.
Robots.txt Problems
Google reminded us that if the robots.txt file is unreachable, they won’t crawl the entire site!
The robots.txt file is plain text code that tells search engines what they can and cannot crawl. You can use robots.txt to manage crawling traffic, which could overwhelm your server, and block resource files, such as images and scripts.
Robots.txt should not be used to keep a web page out of search engine results although robots.txt can usually keep a page off of the search results. If you do block a page with the robots.txt file, it may still appear in search results but it will look something like this. The proper way for keeping a page out of the search results is to use noindex directives or password-protect the page.
As you can see from the Google slide below, about one in four websites’ robot-txt is unreachable by Google! This means that Google won’t crawl the entire site, which could have devastating impacts for your SEO.
#gwcps pic.twitter.com/S1bB6obXEz
— MyCool King (@iPullRank) November 4, 2019
Before you create or edit a robots.txt file, make sure you read and understand the full syntax of robots.txt files.
In order for Google and other search engines to reach your robots.txt file, it must be located in the website’s top-level directory: www.example.com/robots.txt. It should also be accessible through the appropriate protocol and port number.
Here are some suggestions provided by Google:
- Use redirects to clue us into your site redesign.
- Send us meaningful HTTP result codes.
- Check your rel=canonical links.
- Use hreflang links to help us localize.
- Keep reporting hijacking cases to the forums.
- Secure dependencies for secure pages.
- Keep canonical signals unambiguous.
Test your robot.txt file with Google’s robots.txt Tester.
HTTP vs. HTTPS

HTTPS (Hypertext Transfer Protocol Secure) is a more secure internet communications protocol than HTTP. Basically, HTTP sites aren’t encrypted and therefore aren’t secure. Ever since Google warned everyone that they would start using HTTPS as a ranking signal, there’s been a rush to migrate sites over to the more secure protocol.
HTTPS has really grown significantly in a few years, but there’s still a bunch of room. Use secure protocols, folks! #gwcps pic.twitter.com/DaZDAltuZF
— 🍌 John 🍌 (@JohnMu) November 4, 2019
Still, about 75% of the sites that Google crawls now use HTTPS. That means that one in four websites are still using the unsecured HTTP protocol.
HTTPS should be used everywhere to make the internet safer and more secure. As more time goes by, Google will start to strengthen the ranking signal of HTTPS. If don’t have HTTPS, learn how to migrate your site from HTTP to HTTPS.
It not only protects your site, but it also protects the information of your website visitors. If your site still hasn’t adopted HTTPS, Chrome will label your site “Not Secure” or “Dangerous” to the left of the web address. If you have HTTPS, Chrome will give your site a “Secure” label with a locked padlock symbol to indicate the security of your website.
Learn how to prevent and fix security breaches on your website.
Emojis

It took a awhile, but Google now returns results for emoji queries.
Google sees over one million searches on emojis per day 🤯 and it took Google a year to add the ability to search for emojis in search. #gwcps
— Barry Schwartz (@rustybrick) November 4, 2019
Google BERT (Bidirectional Encoder Representations from Transformers)
Google will start using BERT more, which is basically their neural network based technology that makes it easier to analyze natural language queries.
This update has already started to impact the search results, including featured snippets. Basically, it allows Google to better understand language, especially longer, more nuanced search queries.
Take a look at the example below to see how BERT improves search engine results:
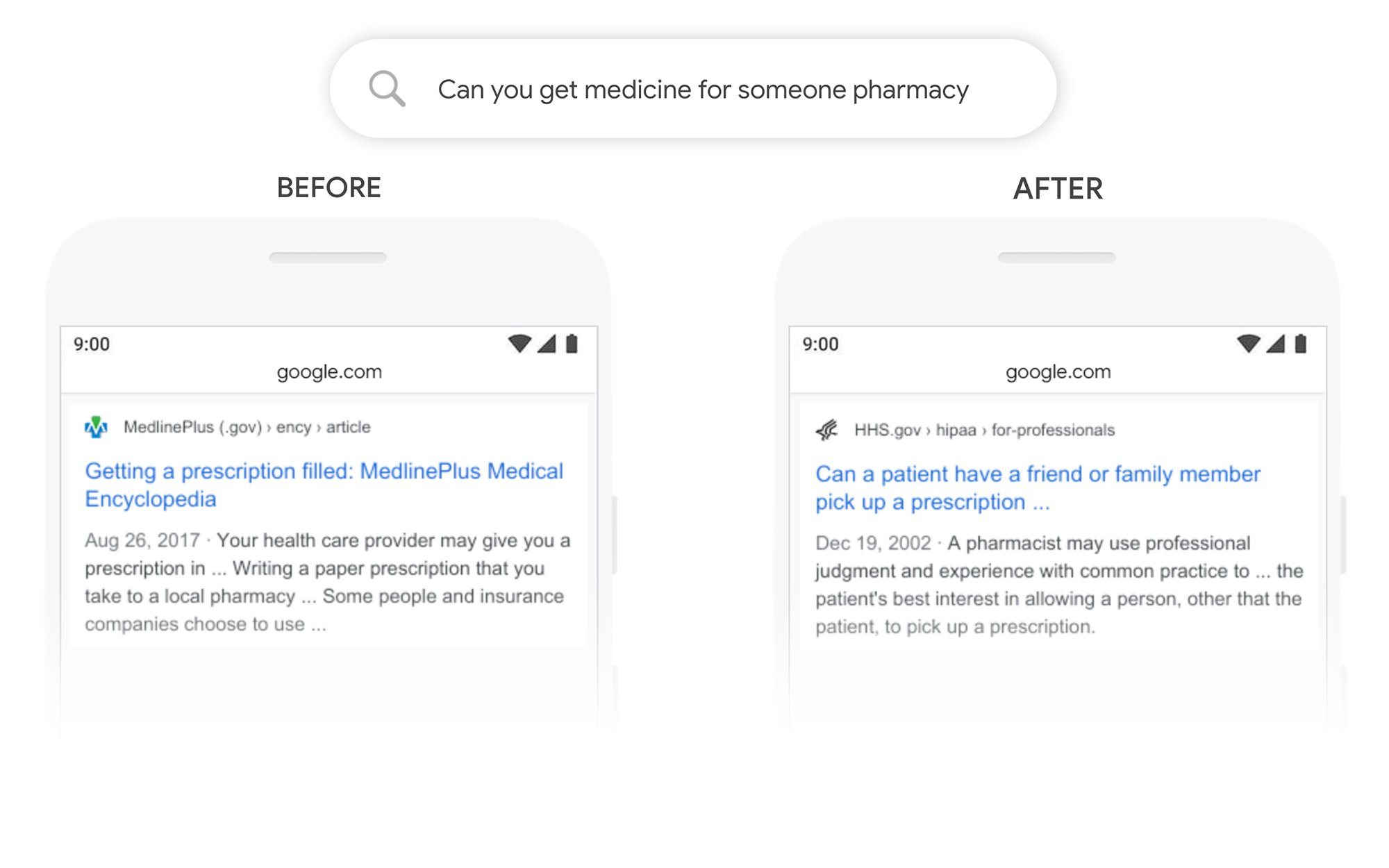
Source: Google
While BERT isn’t replacing RankBrain, it is sometimes used as an additional method for understanding a query. Google sometimes uses multiple methods when analyzing a search query.
There is no real way to optimize for BERT other than creating great content using natural language.
Those were the main takeaways, but there’s always more to learn. To stay up-to-date with all the latest in digital marketing, follow VitalStorm on Twitter, Facebook, and Instagram.